UPDATE (13 June 2019): This post now includes an additional step: Data Cleaning. I learnt about this in the second lesson of the fastai course that I have been following. I was able to remove the images that weren’t good enough for my data set (take a look at top_losses images in Step 4).
This blog post is actually a jupyter notebook, converted to markdown. If interested, you can find this notebook here.
After watching the first lesson video of the fastai course, ‘Practical Deep Learning for Coders’, I was moved. All those things that seemed would take years for me to achieve were now at my fingertips.
The thing is, I am a person who likes to front-load on theory, understanding how every small component works in the ultimate big picture. But this approach is very, very frustrating. I started studying from a book called ‘Pattern Recognition and Machine Learning’ by Christopher M. Bishop. I enjoyed the math at first, but then it started getting on my nerves. In this case, I wanted to learn by doing. So, after researching a little online, I finally came across fastai. I like how they first teach how the code works and then they teach why it works. The course is awesome. After the first lesson, I wanted to create an image classifier too, so I made one which classifies a given image into two categories: anime or cartoon.
So before starting, I tried to find out if someone else had also had this grand idea before. And sure enough, there were quite a few! Great minds think alike!
I first found a paper titled ‘Are Anime Cartoons?’ by ‘Chai, Ramesh, Yeo’. You can read it here. It helped me understand a little about how CNNs actually work. This talked about how CNN models outperform MLP models in the cases where a spatially aware algorithm is necessary to classify images. Good for me, because that’s exactly what the first fastai lesson was about. We learnt how to train pretrained models (like resnet34 and resnet50) using the principles of transfer learning and how to further fine-tune these models to better fit our data. This video also helped me understand CNNs.
The Project
Step 1: Gather Data
The fastai library has a neat feature which allows you to download pictures from a list of their links. So, I created two csv files containing only the links of the anime and cartoon images. For the anime pictures, I used this dataset. For the cartoon pictures, I made use of the Fatkun Batch Download Image chrome browser extension to extract about 250 image links.
I feel that both the datasets could have been better curated for this project.
Moving on, I uploaded the csv files to my google cloud platform server and with the help of the fastai library downloaded the images into two separate folders.
%reload_ext autoreload
%autoreload 2
%matplotlib inlinefrom fastai.vision import *
from fastai.metrics import error_ratebs = 64path = Path('/home/jupyter/tutorials/data/anime-vs-cartoon')classes = ['anime','cartoon']
for c in classes:
print(c)
folder = c
file = 'urls_%s.csv' % c
dest = path/folder
dest.mkdir(parents=True, exist_ok=True)
download_images(path/file, dest, max_pics=1000)
verify_images(path/c, delete=True, max_size=500)Step 2: Transform & View Data
Before training our model, we must normalise our images. The fastai library provides a really cool class called ‘ImageDataBunch’ which allows us to do operations on our image datasets in bulk. You can find out more about this class in the fastai docs here.
np.random.seed(2)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2, ds_tfms=get_transforms(),
size=224, num_workers=4).normalize(imagenet_stats)# This cell should be run after Step 5:Data Cleaning (if required)
# np.random.seed(42)
# data = ImageDataBunch.from_csv(path, folder=".", valid_pct=0.2, csv_labels='cleaned.csv',
# ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)data.show_batch(rows = 3, figsize=(8,6))
data.classes, data.c, len(data.train_ds), len(data.valid_ds)(['anime', 'cartoon'], 2, 421, 105)Step 3: Train Model
We can finally start training our model. For this project I decided to go with the ResNet34 model.
learn = cnn_learner(data, models.resnet34, metrics=error_rate)learn.fit_one_cycle(4)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.735565 | 0.621040 | 0.380952 | 00:07 |
| 1 | 0.421396 | 0.046641 | 0.009524 | 00:03 |
| 2 | 0.296799 | 0.016185 | 0.009524 | 00:03 |
| 3 | 0.222645 | 0.011620 | 0.009524 | 00:03 |
learn.save('stage-1')Step 4: Interpretation
interp = ClassificationInterpretation.from_learner(learn)
losses, idxs = interp.top_losses()
len(data.valid_ds)==len(losses)==len(idxs)Trueinterp.plot_confusion_matrix()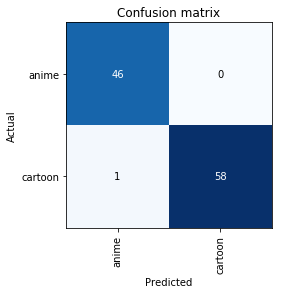
interp.plot_top_losses(4, figsize=(6, 6), heatmap=False)
Looking at the above pictures, it makes sense why our model classified these incorrectly! Even a casual anime viewer would be confused when looking at these pictures. Once again, please excuse me for my poorly curated data sets.
Step 5: Data Cleaning
As can be seen above, there are some images in the data set which don’t belong there. I used the ImageCleaner widget from the fastai library to remove these images.
from fastai.widgets import *db = (ImageList.from_folder(path)
.split_none()
.label_from_folder()
.transform(get_transforms(), size=224)
.databunch()
)learn_cln = cnn_learner(db, models.resnet34, metrics=error_rate)
learn_cln.load('stage-1');ds, idxs = DatasetFormatter().from_toplosses(learn_cln)ImageCleaner(ds, idxs, path)We can now go back to Step 2 and train a new model on the cleaned data set.
Step 6: Fine Tuning
Let’s see if we can reduce the error rate by choosing a range of learning rate optimum for this model.
learn.unfreeze()
learn.fit_one_cycle(1)
learn.lr_find()
learn.recorder.plot()| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.102109 | 0.044281 | 0.019048 | 00:04 |
LR Finder is complete, type {learner_name}.recorder.plot() to see the graph.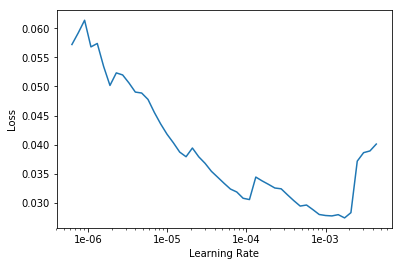
learn.unfreeze()
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4))| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.040849 | 0.050569 | 0.019048 | 00:04 |
| 1 | 0.036746 | 0.045013 | 0.019048 | 00:04 |
The train_loss variable has gone down considerably. This probably means that the model is overfitting the training data. Let’s just revert back to the old model (before the fine tuning).
learn.load('stage-1')Step 7: Testing
This step was a lot of fun! I tested the model on a lot of images from my favourite anime and cartoons, and the thing that surprised me the most was, the model was actually working! I was a little sceptical at first, but after testing it a couple of times I was pretty satisfied with it’s performance. It seemed to guess the image correctly most of the time, save for a few instances. For example, it incorrectly identified a scene from Boku no Hero Academia as a cartoon.
learn.export()img = open_image(Path('/home/jupyter/tutorials/data/test/bnha3.jpg'))
img
learn = load_learner(path)
learn.predict(img)(Category cartoon, tensor(1), tensor([0.1647, 0.8353]))As you can see, the model isn’t perfect! Also, there are many things that I do not understand very well yet, like
- the behaviour of the error_rate variable above (why does it become constant?)
- how do I properly interpret the loss vs learning rate plot?
- how can I ensure that my data set is good enough? (exploring concepts like normalisation)
- and some more
I will try to find the answers to these questions as I progress further in the course, discuss in the forums etc.. I will post whatever I learn here on this blog.
Step 8: Put Model in Production
This was something I made just for fun, as a project to test out what I had learnt. I have no plans to put this in production anytime soon, for this is in no means perfect and is only a trivial application of deep learning. However, I may eventually create a very basic android app just to see how I can integrate deep learning with an app running on a mobile device.
Future Projects
I have only just begun learning deep learning, but I am already having a lot of fun. You can expect the blog posts to get more frequent, because I have decided to document each step of my journey here. If you have any comments or questions, feel free to drop an email to me!